Request Resolution Time Prediction through Clustering Analysis
The project aimed to enhance a Customer Relationship Management (CRM) system by predicting request resolution times through clustering analysis. Using K-means clustering and Python, service requests were grouped based on various attributes, allowing for efficient resource allocation and improved operational efficiency. This innovative approach enabled data-driven decision-making, leading to better customer satisfaction. The project's success expanded expertise in data analytics and predictive modeling, reaffirming a commitment to delivering exceptional results through excellence and innovation.
Project Objective
The Challenge:
The objective was to optimise the Customer Relationship Management (CRM) system by utilising data analytics to predict the resolution times of service requests. The challenge was to predict request resolution times by clustering service requests based on multiple attributes, including Area name, department name, service name, service category, status, service type, source of creation, and Request resolution time.
Complexity and Innovation:
This project required the application of advanced clustering techniques to a diverse dataset. The innovative approach of combining clustering analysis with request resolution prediction sets a new standard for enhancing resource allocation and service delivery.
The Process
Client Collaboration:
The project began with extensive consultations to understand the objectives and challenges related to request management and its resolution times.
Technology Stack:
To accomplish this task, we leveraged Python and popular libraries such as Pandas, LightGBM for data preprocessing and K-means clustering for analysis. This technology stack provided flexibility and robust capabilities for data analytics.
Dataset:
The project utilised a CRM dataset, encompassing essential attributes, including request details, departmental categorizations, service types, service categories, request statuses, source of creation, and Request resolve time.
Feature Inventory
Clustering Analysis: Utilised K-means clustering to group service requests based on multiple attributes, enabling the categorization of requests into meaningful clusters.
Request Resolution Prediction: Predicted Request resolution time for new service requests by assigning them to appropriate clusters and leveraging cluster-based averages.
Resource Allocation Optimization: The project empowered the organisation to optimise resource allocation by accurately predicting request resolution times, leading to improved operational efficiency.
Operational Efficiency: The clustering-based approach streamlined service request handling by grouping similar requests together, resulting in more efficient processing.
Customer Satisfaction Improvement: By making data-driven decisions related to request prioritisation and adherence to service level agreements, the project contributed to enhanced customer satisfaction.
The Results
The project successfully achieved its objective of predicting request resolution times through clustering analysis. This approach enabled the organisation to optimise resource allocation, prioritise requests effectively, and ensure customer satisfaction. The application of clustering techniques to CRM data represents a significant step toward data-driven decision-making within the organisation.
This project expanded our expertise in data analytics, clustering, and predictive modelling. We are now well-equipped to apply these valuable insights and methodologies to similar projects in the future. Our commitment to excellence and innovation has been evident throughout this endeavour, reinforcing our dedication to delivering exceptional results.
Visual Designs
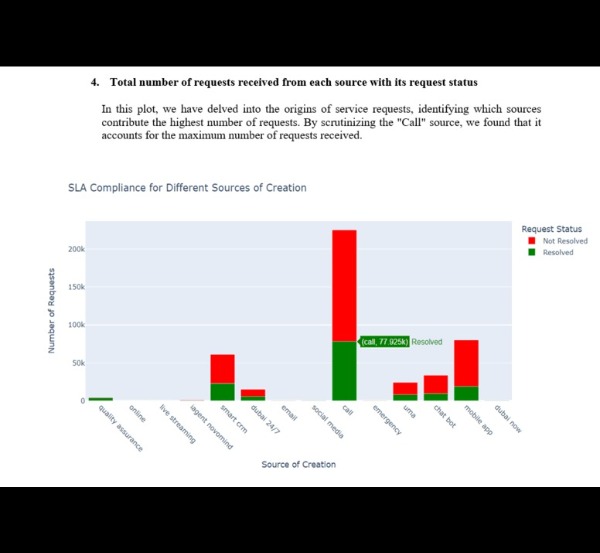
SLA Compliance for Different Source
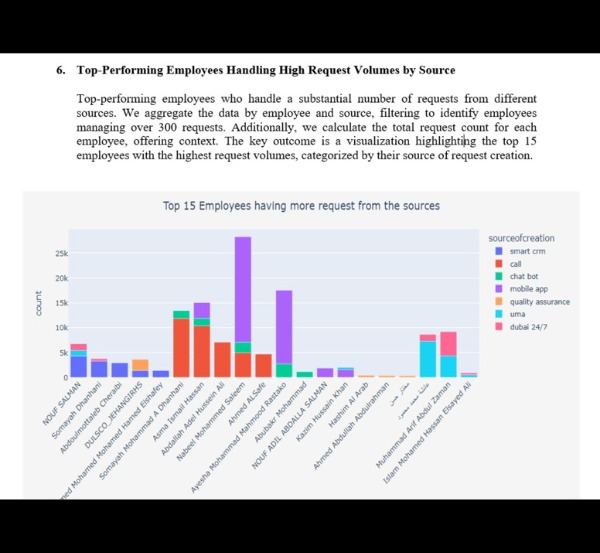
Top-Performing Employees Handling High Request Volumes
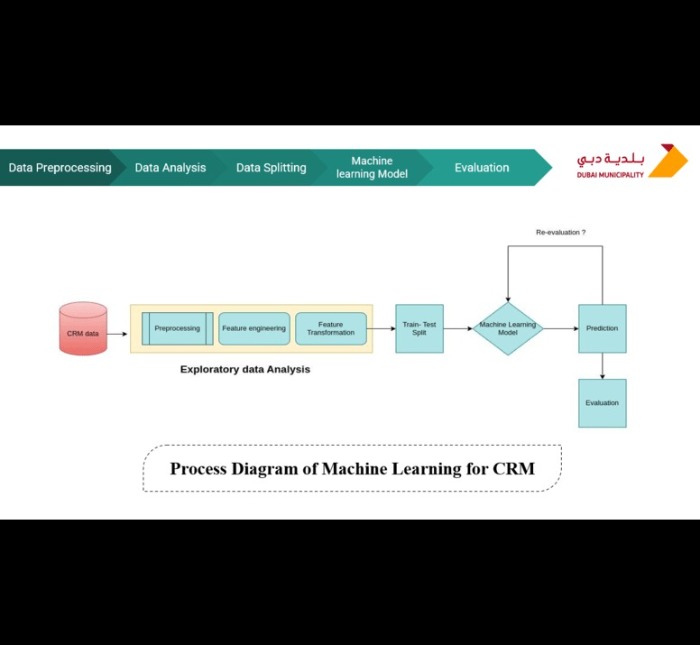
Process Diagramof ML for CRM
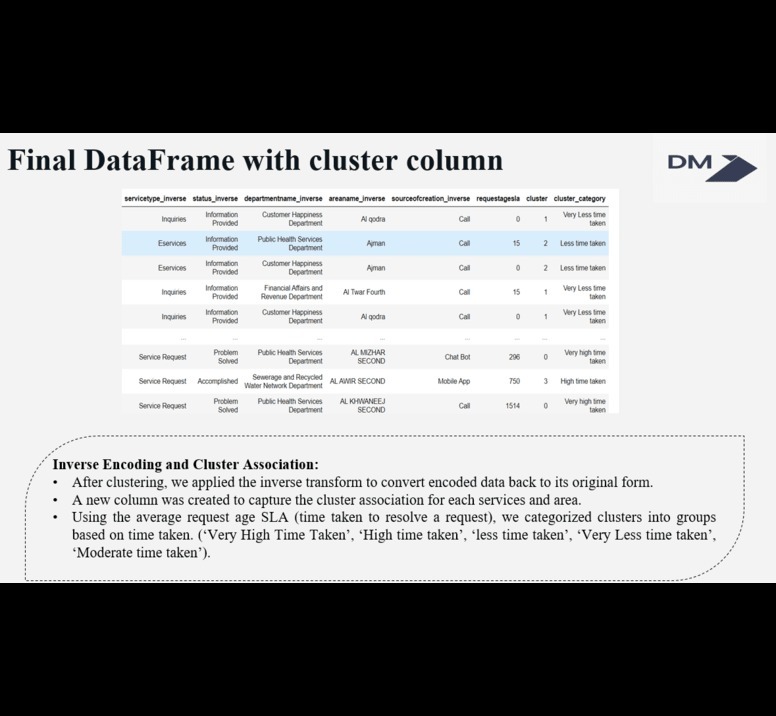
Final DataFrame with Cluster Columns
TECHNOLOGIES USED
Scikit Learn
Matplotlib

Spark
